Trí tuệ nhân tạo (AI) đang đứng trước một “điểm mù” chí mạng: khả năng hiểu các từ phủ định như “không” hay “không có”. Nghiên cứu mới từ Viện Công nghệ Massachusetts (MIT) chỉ ra rằng thiếu sót này không chỉ là một lỗi kỹ thuật đơn thuần, mà có thể dẫn đến những hậu quả khôn lường, đặc biệt trong các lĩnh vực nhạy cảm như y tế, nơi một quyết định sai lầm có thể trả giá bằng tính mạng.
Key Takeaways
- Các mô hình AI hiện tại gặp khó khăn trong việc hiểu và xử lý các từ phủ định.
- Sự thiếu hụt này có thể dẫn đến những sai sót nghiêm trọng, đặc biệt trong các ứng dụng quan trọng như y tế.
- Nghiên cứu của MIT chỉ ra rằng các Mô hình Ngôn ngữ-Thị giác (VLM) thường bỏ qua hoặc hiểu sai các phủ định.
- “Thiên kiến khẳng định” trong dữ liệu huấn luyện là một trong những nguyên nhân chính gây ra vấn đề này.
- Việc huấn luyện lại các VLM với bộ dữ liệu bao gồm cả các ví dụ phủ định có thể cải thiện hiệu suất.
Khi AI “bỏ qua” sự phủ định: Nguy cơ tiềm ẩn từ phòng thí nghiệm đến thực tiễn
Hãy tưởng tượng một bác sĩ chẩn đoán hình ảnh đang xem xét X-quang phổi của một bệnh nhân mới. Cô nhận thấy bệnh nhân có dấu hiệu sưng mô nhưng tim không to. Để tăng tốc độ chẩn đoán, bác sĩ có thể sử dụng một Mô hình Ngôn ngữ-Thị giác (VLM) để tìm kiếm các báo cáo từ những bệnh nhân tương tự. Nhưng nếu mô hình này nhầm lẫn, xác định các báo cáo của bệnh nhân vừa sưng mô vừa có tim to, chẩn đoán rất có thể sẽ đi chệch hướng nghiêm trọng. Bởi lẽ, sưng mô kèm tim to nhiều khả năng liên quan đến bệnh lý tim mạch, trong khi sưng mô mà không có tim to lại gợi ý nhiều nguyên nhân tiềm ẩn khác.
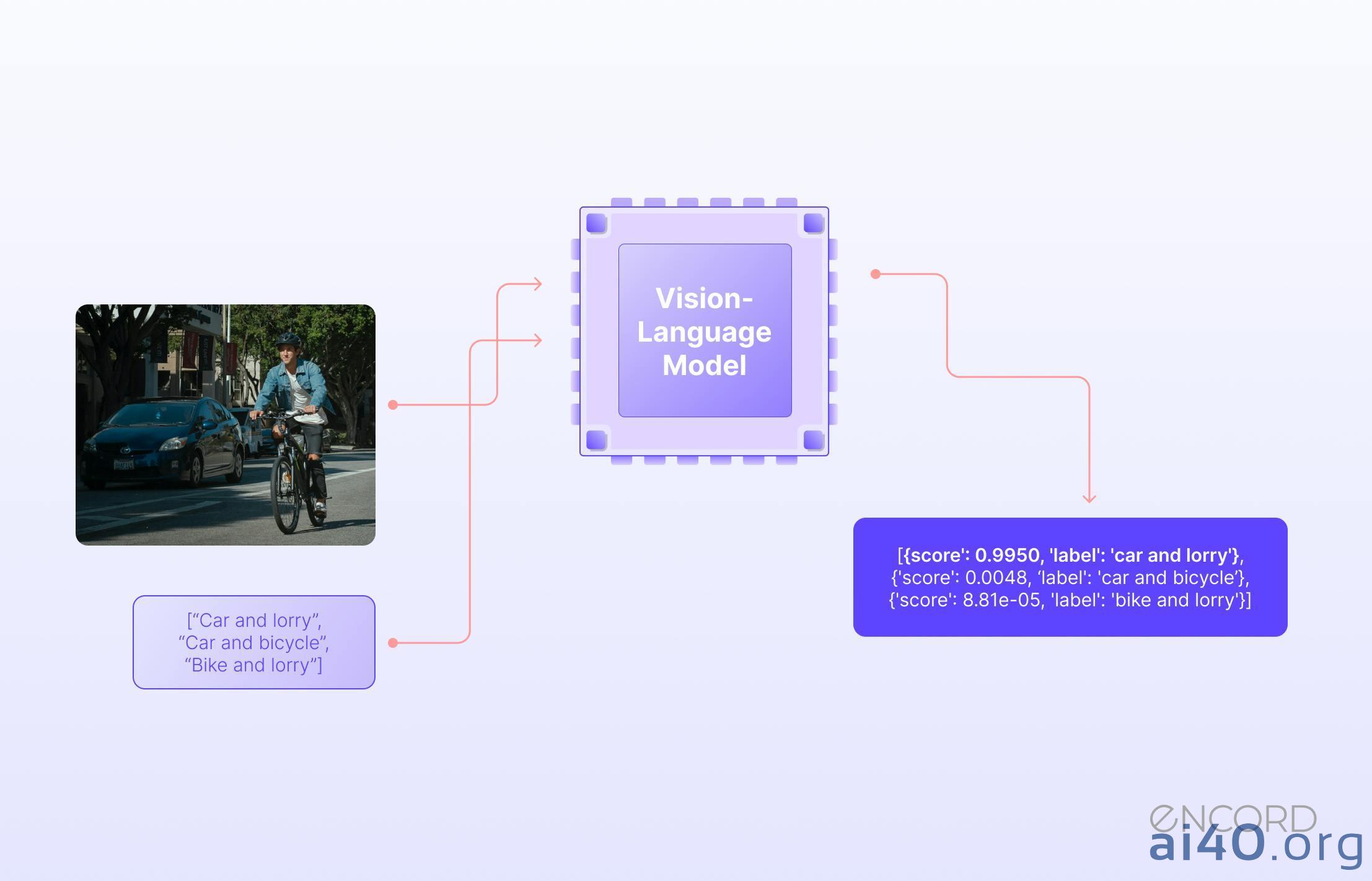
Nghiên cứu của MIT đã phơi bày một sự thật đáng báo động: các VLM hiện tại rất dễ mắc phải sai lầm kiểu này trong thực tế vì chúng không thực sự “hiểu” được ý nghĩa của sự phủ định. Kumail Alhamoud, nghiên cứu sinh MIT và tác giả chính của nghiên cứu, cảnh báo: “Những từ phủ định đó có thể tác động rất lớn, và nếu chúng ta cứ sử dụng các mô hình này một cách mù quáng, chúng ta có thể đối mặt với những hậu quả thảm khốc.”
Thử nghiệm bóc trần điểm yếu
Các nhà nghiên cứu đã kiểm tra khả năng của VLM trong việc xác định sự phủ định trong chú thích hình ảnh. Kết quả cho thấy, hiệu suất của các mô hình này thường không khá hơn việc đoán ngẫu nhiên. Dựa trên những phát hiện đó, nhóm đã tạo ra một bộ dữ liệu hình ảnh với các chú thích tương ứng bao gồm các từ phủ định mô tả các đối tượng bị thiếu.
Việc huấn luyện lại một VLM với bộ dữ liệu này cho thấy sự cải thiện về hiệu suất khi mô hình được yêu cầu truy xuất hình ảnh không chứa các đối tượng nhất định. Nó cũng tăng cường độ chính xác trong việc trả lời các câu hỏi trắc nghiệm với các chú thích bị phủ định. Tuy nhiên, các nhà nghiên cứu thận trọng rằng cần nhiều nỗ lực hơn nữa để giải quyết tận gốc vấn đề này.
Gốc rễ của vấn đề: “Thiên kiến khẳng định” trong dữ liệu huấn luyện
Mô hình Ngôn ngữ-Thị giác (VLM) được huấn luyện bằng cách sử dụng các bộ sưu tập khổng lồ gồm hình ảnh và chú thích tương ứng. Chúng học cách mã hóa cả hình ảnh và văn bản thành các biểu diễn vector, sao cho hình ảnh và chú thích mô tả nó có vector tương tự nhau.
Giáo sư Marzyeh Ghassemi, tác giả cấp cao của nghiên cứu, giải thích: “Các chú thích thường diễn tả những gì có trong hình ảnh – chúng là một nhãn khẳng định. Và đó chính là toàn bộ vấn đề. Không ai nhìn vào một bức ảnh con chó nhảy qua hàng rào và chú thích rằng ‘một con chó nhảy qua hàng rào, không có trực thăng’.” Chính vì các bộ dữ liệu hình ảnh-chú thích thiếu vắng các ví dụ về phủ định, VLM không bao giờ học được cách xác định nó.
Thử thách kép cho VLM
Để đào sâu hơn, các nhà nghiên cứu đã thiết kế hai bài kiểm tra benchmark.
Thứ nhất, họ sử dụng một mô hình ngôn ngữ lớn (LLM) để tái chú thích hình ảnh, yêu cầu LLM nghĩ về các đối tượng liên quan không có trong ảnh và viết chúng vào chú thích. Sau đó, họ kiểm tra các VLM bằng cách gợi ý bằng các từ phủ định để truy xuất hình ảnh chứa một số đối tượng nhất định, nhưng không chứa các đối tượng khác.
Thứ hai, họ thiết kế các câu hỏi trắc nghiệm yêu cầu VLM chọn chú thích phù hợp nhất từ một danh sách các lựa chọn gần giống nhau, chỉ khác biệt ở việc thêm tham chiếu đến một đối tượng không xuất hiện trong ảnh hoặc phủ định một đối tượng có trong ảnh.

Kết quả thật đáng thất vọng: các mô hình thường xuyên thất bại ở cả hai nhiệm vụ. Hiệu suất truy xuất hình ảnh giảm gần 25% với các chú thích bị phủ định. Khi trả lời câu hỏi trắc nghiệm, các mô hình tốt nhất chỉ đạt độ chính xác khoảng 39%, nhiều mô hình hoạt động ở mức hoặc thậm chí dưới mức ngẫu nhiên. Một lý do chính là “lối tắt” mà các nhà nghiên cứu gọi là “thiên kiến khẳng định” (affirmation bias) – VLM bỏ qua các từ phủ định và chỉ tập trung vào các đối tượng có trong hình ảnh. Alhamoud nhấn mạnh: “Điều này không chỉ xảy ra với các từ như ‘không’ và ‘chẳng’. Bất kể bạn diễn đạt sự phủ định hay loại trừ như thế nào, các mô hình sẽ đơn giản là bỏ qua nó.”
Hướng đi nào cho một AI “thấu hiểu” hơn?
Nhận thức được rằng VLM thường không được huấn luyện với các chú thích hình ảnh có chứa phủ định, các nhà nghiên cứu đã phát triển các bộ dữ liệu tích hợp từ phủ định như một bước đi đầu tiên. Sử dụng một bộ dữ liệu với 10 triệu cặp hình ảnh-chú thích, họ đã thúc đẩy một LLM đề xuất các chú thích liên quan chỉ rõ những gì bị loại trừ khỏi hình ảnh, tạo ra các chú thích mới với từ phủ định. Họ đặc biệt cẩn trọng để đảm bảo các chú thích tổng hợp này vẫn đọc tự nhiên, tránh trường hợp VLM thất bại khi đối mặt với các chú thích phức tạp hơn do con người viết.
Kết quả cho thấy việc tinh chỉnh VLM với bộ dữ liệu này đã mang lại những cải thiện đáng kể, tăng khả năng truy xuất hình ảnh khoảng 10% và cải thiện hiệu suất trả lời câu hỏi trắc nghiệm khoảng 30%. Dù vậy, Alhamoud thừa nhận: “Giải pháp của chúng tôi không hoàn hảo. Chúng tôi chỉ đang tái chú thích các bộ dữ liệu, một dạng tăng cường dữ liệu. Chúng tôi thậm chí còn chưa tác động đến cách các mô hình này hoạt động, nhưng chúng tôi hy vọng đây là một tín hiệu cho thấy đây là một vấn đề có thể giải quyết được.”
Trong tương lai, các nhà nghiên cứu có thể mở rộng công việc này bằng cách dạy VLM xử lý văn bản và hình ảnh một cách riêng biệt, điều này có thể cải thiện khả năng hiểu phủ định của chúng. Ngoài ra, việc phát triển các bộ dữ liệu bổ sung bao gồm các cặp hình ảnh-chú thích cho các ứng dụng cụ thể, chẳng hạn như chăm sóc sức khỏe, là vô cùng cần thiết.
Kết luận
Nghiên cứu từ MIT đã gióng lên một hồi chuông cảnh báo về một thiếu sót nền tảng trong các mô hình AI ngôn ngữ-thị giác hiện tại: sự “mù mờ” trước khái niệm phủ định. Đây không chỉ là một thách thức kỹ thuật, mà còn là một vấn đề đạo đức và an toàn, đặc biệt khi AI ngày càng được tích hợp sâu rộng vào các lĩnh vực có ảnh hưởng lớn đến đời sống con người như y tế hay sản xuất. Phát hiện này nhấn mạnh sự cấp thiết của việc đánh giá kỹ lưỡng và phát triển các phương pháp huấn luyện AI mạnh mẽ hơn, có khả năng “thẩm thấu” được sự phức tạp của ngôn ngữ tự nhiên, bao gồm cả những sắc thái tinh tế như phủ định. Con đường phía trước đòi hỏi sự cẩn trọng, đầu tư vào nghiên cứu sâu hơn và một cam kết không ngừng nghỉ để đảm bảo rằng công nghệ AI phục vụ lợi ích của con người một cách an toàn và đáng tin cậy.






