Key Takeaways
- AlphaEvolve là một tác nhân mã hóa dựa trên nguyên lý tiến hóa, có khả năng tự khám phá các thuật toán và giải pháp khoa học đột phá.
- AlphaEvolve sử dụng vòng lặp tiến hóa từ Mô hình Ngôn ngữ Lớn (LLM) để tự cải tiến mã nguồn thông qua đột biến, đánh giá, chọn lọc.
- AlphaEvolve đã phá vỡ kỷ lục toán học 56 năm bằng cách khám phá ra thuật toán mới để nhân ma trận 4×4 chỉ với 48 phép nhân vô hướng.
- AlphaEvolve giúp tối ưu hóa hạ tầng của Google, cải thiện hiệu suất lập lịch trung tâm dữ liệu, huấn luyện Gemini và thiết kế mạch TPU.
- AlphaEvolve là một bước tiến quan trọng hướng tới Trí tuệ nhân tạo tổng quát (AGI) và Siêu trí tuệ nhân tạo (ASI) nhờ khả năng tự chủ sáng tạo và tự cải tiến đệ quy.

AlphaEvolve: “Bộ não” AI tự tiến hóa và khám phá thuật toán
Khác biệt hoàn toàn với các phương pháp tinh chỉnh tĩnh (static fine-tuning) hay dựa vào bộ dữ liệu được gán nhãn bởi con người, AlphaEvolve mở ra một hướng đi mới, tập trung vào sáng tạo tự chủ, đổi mới thuật toán và tự cải tiến liên tục. Đây là một bước ngoặt thực sự, có thể định hình lại cách chúng ta tiếp cận nghiên cứu khoa học và phát triển công nghệ.
Cơ chế hoạt động: Vòng lặp tiến hóa từ Mô hình Ngôn ngữ Lớn (LLM)
Cốt lõi của AlphaEvolve là một quy trình tiến hóa khép kín, được vận hành bởi các Mô hình Ngôn ngữ Lớn (LLM). Quy trình này không chỉ đơn thuần tạo ra kết quả mà còn thực hiện các tác vụ phức tạp hơn: đột biến (mutate), đánh giá (evaluate), chọn lọc (select) và cải tiến mã nguồn (improve code) qua nhiều thế hệ. AlphaEvolve khởi đầu với một chương trình ban đầu và lặp đi lặp lại việc tinh chỉnh nó bằng cách đưa vào các thay đổi có cấu trúc một cách cẩn thận.
Những thay đổi này được thể hiện dưới dạng các “diffs” (khác biệt mã) do LLM tạo ra – tức là những sửa đổi mã được đề xuất bởi mô hình ngôn ngữ dựa trên các ví dụ trước đó và hướng dẫn cụ thể. Trong kỹ thuật phần mềm, “diff” chỉ sự khác biệt giữa hai phiên bản của một tệp, thường làm nổi bật các dòng bị xóa, thay thế hoặc thêm mới. Với AlphaEvolve, LLM tạo ra các “diffs” này bằng cách phân tích chương trình hiện tại và đề xuất các chỉnh sửa nhỏ – thêm một hàm, tối ưu hóa một vòng lặp, hoặc thay đổi một siêu tham số – dựa trên một “prompt” (câu lệnh đầu vào) bao gồm các chỉ số hiệu suất và các chỉnh sửa thành công trước đó.
Sức mạnh của “diffs” và đánh giá tự động
Mỗi chương trình sau khi được sửa đổi sẽ được kiểm tra bằng các bộ đánh giá tự động được thiết kế riêng cho từng tác vụ. Những ứng viên hiệu quả nhất sẽ được lưu trữ, tham chiếu và kết hợp lại để làm nguồn cảm hứng cho các vòng lặp tương lai. Theo thời gian, vòng lặp tiến hóa này dẫn đến sự xuất hiện của các thuật toán ngày càng tinh vi – thường vượt trội hơn cả những thuật toán do các chuyên gia con người thiết kế.
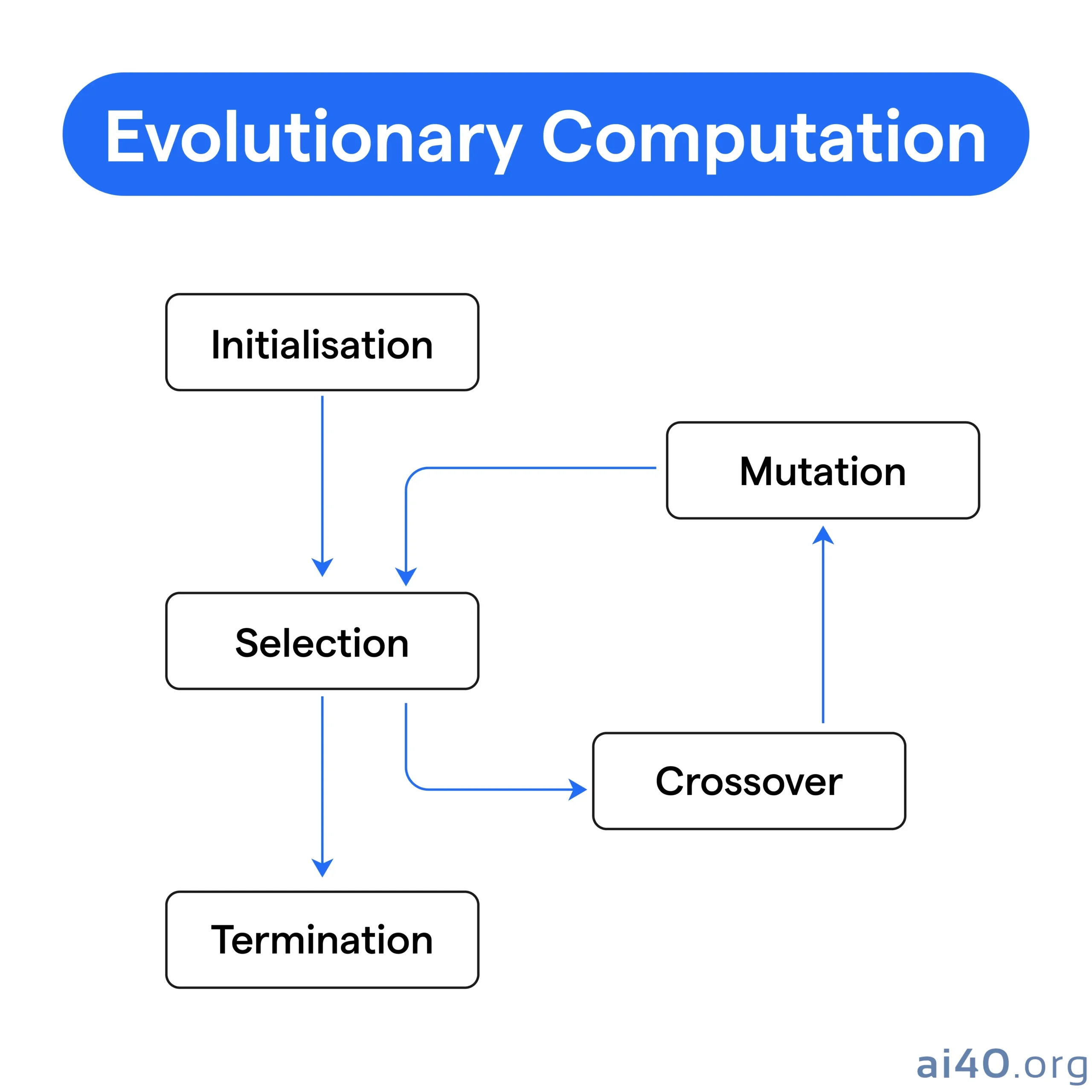
Nền tảng khoa học của AlphaEvolve dựa trên các nguyên lý của tính toán tiến hóa (evolutionary computation) – một nhánh phụ của trí tuệ nhân tạo lấy cảm hứng từ quá trình tiến hóa sinh học. Hệ thống bắt đầu với một đoạn mã cơ bản, coi đó là một “sinh vật” ban đầu. Qua các thế hệ, AlphaEvolve sửa đổi đoạn mã này – tạo ra các biến thể hay “đột biến” – và đánh giá “mức độ thích nghi” của mỗi biến thể bằng một hàm tính điểm được xác định rõ ràng. Các biến thể hoạt động tốt nhất sẽ “sống sót” và đóng vai trò làm khuôn mẫu cho thế hệ tiếp theo.
Vòng lặp tiến hóa này được điều phối thông qua:
* Lấy mẫu Prompt (Prompt Sampling): AlphaEvolve xây dựng các prompt bằng cách chọn và nhúng các mẫu mã thành công trước đó, chỉ số hiệu suất và hướng dẫn cụ thể cho từng tác vụ.
* Đột biến và Đề xuất Mã (Code Mutation and Proposal): Hệ thống sử dụng kết hợp các LLM mạnh mẽ – như Gemini 2.0 Flash và Pro – để tạo ra các sửa đổi cụ thể cho mã nguồn hiện tại dưới dạng “diffs”.
* Cơ chế Đánh giá (Evaluation Mechanism): Một hàm đánh giá tự động sẽ thẩm định hiệu suất của mỗi ứng viên bằng cách thực thi nó và trả về điểm số vô hướng.
* Cơ sở dữ liệu và Bộ điều khiển (Database and Controller): Một bộ điều khiển phân tán điều phối vòng lặp này, lưu trữ kết quả trong cơ sở dữ liệu tiến hóa và cân bằng giữa khám phá và khai thác thông qua các cơ chế như MAP-Elites.
Quy trình tiến hóa tự động, giàu phản hồi này khác biệt hoàn toàn so với các kỹ thuật tinh chỉnh tiêu chuẩn. Nó trao quyền cho AlphaEvolve tạo ra các giải pháp mới lạ, hiệu suất cao và đôi khi là phản trực giác – đẩy xa hơn nữa ranh giới những gì học máy có thể tự chủ đạt được.
So sánh với RLHF: Bước nhảy vọt về khả năng tự chủ
Để đánh giá đúng sự đổi mới của AlphaEvolve, điều quan trọng là phải so sánh nó với Học tăng cường từ phản hồi của con người (RLHF), một phương pháp chủ đạo được sử dụng để tinh chỉnh các mô hình ngôn ngữ lớn.
Trong RLHF, sở thích của con người được sử dụng để huấn luyện một mô hình phần thưởng, mô hình này sau đó sẽ hướng dẫn quá trình học của LLM thông qua các thuật toán học tăng cường như Proximal Policy Optimization (PPO). RLHF cải thiện sự phù hợp và tính hữu dụng của mô hình, nhưng nó đòi hỏi sự tham gia sâu rộng của con người để tạo dữ liệu phản hồi và thường hoạt động trong một chế độ tinh chỉnh tĩnh, một lần.
Ngược lại, AlphaEvolve:
* Loại bỏ phản hồi của con người khỏi vòng lặp, thay vào đó là các bộ đánh giá có thể thực thi bằng máy.
* Hỗ trợ học liên tục (continual learning) thông qua chọn lọc tiến hóa.
* Khám phá không gian giải pháp rộng lớn hơn nhiều nhờ các đột biến ngẫu nhiên và thực thi không đồng bộ.
* Có thể tạo ra các giải pháp không chỉ phù hợp mà còn mới lạ và có ý nghĩa khoa học.
Nói một cách dễ hiểu, nếu RLHF tinh chỉnh hành vi, thì AlphaEvolve khám phá và phát minh. Sự khác biệt này mang tính quyết định khi xem xét quỹ đạo tương lai hướng tới AGI: AlphaEvolve không chỉ đưa ra dự đoán tốt hơn – nó tìm ra những con đường mới dẫn đến chân lý.
Những đột phá “không tưởng” của AlphaEvolve
AlphaEvolve đã chứng minh khả năng tạo ra những khám phá mang tính đột phá trong các vấn đề thuật toán cốt lõi, khiến giới chuyên môn không khỏi kinh ngạc.
“Soán ngôi” kỷ lục toán học 56 năm
Đáng chú ý nhất, AlphaEvolve đã khám phá ra một thuật toán mới để nhân hai ma trận giá trị phức 4×4 chỉ sử dụng 48 phép nhân vô hướng. Thành tích này đã vượt qua kết quả 49 phép nhân của Strassen vào năm 1969, phá vỡ một giới hạn lý thuyết tồn tại suốt 56 năm. AlphaEvolve đạt được điều này thông qua các kỹ thuật phân rã tensor (tensor decomposition) tiên tiến mà nó đã tiến hóa qua nhiều thế hệ, vượt trội hơn một số phương pháp hiện đại nhất.
Ngoài phép nhân ma trận, AlphaEvolve còn có những đóng góp đáng kể cho nghiên cứu toán học. Nó được đánh giá trên hơn 50 bài toán mở thuộc các lĩnh vực như tổ hợp, lý thuyết số và hình học. Hệ thống này đã đạt được kết quả tương đương với những kết quả tốt nhất được biết đến trong khoảng 75% trường hợp và vượt qua chúng trong khoảng 20% trường hợp. Những thành công này bao gồm cải tiến Bài toán Chồng chéo Tối thiểu của Erdős, một giải pháp dày đặc hơn cho Bài toán Số Hôn (Kissing Number Problem) trong 11 chiều, và các cấu hình xếp chồng hình học hiệu quả hơn. Những kết quả này nhấn mạnh khả năng của nó hoạt động như một nhà thám hiểm toán học tự chủ – tinh chỉnh, lặp lại và tiến hóa các giải pháp ngày càng tối ưu mà không cần sự can thiệp của con người.
Tối ưu hóa hạ tầng khổng lồ của Google
AlphaEvolve cũng đã mang lại những cải thiện hiệu suất hữu hình trên toàn bộ cơ sở hạ tầng của Google:
* Trong việc lập lịch trung tâm dữ liệu, nó đã phát hiện ra một phương pháp heuristic mới giúp cải thiện việc sắp xếp công việc, phục hồi 0.7% tài nguyên tính toán trước đây bị mắc kẹt.
* Đối với các nhân huấn luyện của Gemini, AlphaEvolve đã thiết kế một chiến lược xếp lớp (tiling) tốt hơn cho phép nhân ma trận, mang lại tốc độ nhân nhanh hơn 23% và giảm 1% tổng thời gian huấn luyện.
* Trong thiết kế mạch TPU, nó đã xác định một sự đơn giản hóa cho logic số học ở cấp độ RTL (Register-Transfer Level), được các kỹ sư xác minh và đưa vào chip TPU thế hệ tiếp theo.
* Nó cũng tối ưu hóa mã FlashAttention do trình biên dịch tạo ra bằng cách chỉnh sửa các biểu diễn trung gian XLA, cắt giảm 32% thời gian suy luận trên GPU.
Cùng với nhau, những kết quả này xác nhận khả năng của AlphaEvolve hoạt động ở nhiều cấp độ trừu tượng – từ toán học biểu tượng đến tối ưu hóa phần cứng cấp thấp – và mang lại lợi ích hiệu suất trong thế giới thực.
Tiềm năng hướng tới AGI và ASI: Khi AI tự tư duy và sáng tạo
AlphaEvolve không chỉ là một công cụ tối ưu hóa – nó là một cái nhìn thoáng qua về một tương lai nơi các tác nhân thông minh có thể thể hiện sự tự chủ sáng tạo. Khả năng của hệ thống trong việc hình thành các vấn đề trừu tượng và thiết kế các phương pháp riêng để giải quyết chúng thể hiện một bước tiến đáng kể hướng tới Trí tuệ nhân tạo tổng quát (AGI). Điều này vượt xa việc dự đoán dữ liệu: nó bao gồm lập luận có cấu trúc, hình thành chiến lược và thích ứng với phản hồi – những dấu hiệu của hành vi thông minh.
Khả năng lặp đi lặp lại việc tạo ra và tinh chỉnh các giả thuyết cũng báo hiệu một sự tiến hóa trong cách máy móc học hỏi. Không giống như các mô hình đòi hỏi đào tạo có giám sát rộng rãi, AlphaEvolve tự cải thiện thông qua một vòng lặp thử nghiệm và đánh giá. Hình thức trí tuệ năng động này cho phép nó điều hướng các không gian vấn đề phức tạp, loại bỏ các giải pháp yếu và nâng cao các giải pháp mạnh hơn mà không cần sự giám sát trực tiếp của con người.
Bằng cách thực thi và xác nhận các ý tưởng của chính mình, AlphaEvolve hoạt động như cả nhà lý thuyết và nhà thực nghiệm. Nó vượt ra ngoài việc thực hiện các tác vụ được xác định trước và đi vào lĩnh vực khám phá, mô phỏng một quy trình khoa học tự chủ. Mỗi cải tiến được đề xuất đều được kiểm tra, đo điểm chuẩn và tái tích hợp – cho phép tinh chỉnh liên tục dựa trên kết quả thực tế thay vì các mục tiêu tĩnh.
Có lẽ đáng chú ý nhất, AlphaEvolve là một ví dụ ban đầu về tự cải tiến đệ quy (recursive self-improvement) – nơi một hệ thống AI không chỉ học mà còn tăng cường các thành phần của chính nó. Trong một số trường hợp, AlphaEvolve đã cải thiện cơ sở hạ tầng đào tạo hỗ trợ các mô hình nền tảng của chính nó. Mặc dù vẫn bị giới hạn bởi các kiến trúc hiện tại, khả năng này đặt ra một tiền lệ. Với nhiều vấn đề hơn được đóng khung trong các môi trường có thể đánh giá, AlphaEvolve có thể mở rộng quy mô hướng tới hành vi ngày càng tinh vi và tự tối ưu hóa – một đặc điểm cơ bản của Siêu trí tuệ nhân tạo (ASI).
Hạn chế và triển vọng tương lai
Hạn chế hiện tại của AlphaEvolve là sự phụ thuộc vào các hàm đánh giá tự động. Điều này giới hạn tiện ích của nó đối với các vấn đề có thể được chính thức hóa bằng toán học hoặc thuật toán. Nó chưa thể hoạt động một cách có ý nghĩa trong các lĩnh vực đòi hỏi sự hiểu biết ngầm của con người, đánh giá chủ quan hoặc thử nghiệm vật lý.
Tuy nhiên, các hướng đi trong tương lai bao gồm:
* Tích hợp đánh giá hỗn hợp: kết hợp suy luận biểu tượng với sở thích của con người và các phê bình bằng ngôn ngữ tự nhiên.
* Triển khai trong các môi trường mô phỏng, cho phép thử nghiệm khoa học hiện thân.
* Chưng cất (distillation) các kết quả đã tiến hóa vào các LLM cơ sở, tạo ra các mô hình nền tảng có khả năng và hiệu quả lấy mẫu cao hơn.
Những quỹ đạo này hướng tới các hệ thống ngày càng có tính tự chủ, có khả năng giải quyết vấn đề tự chủ và có tính rủi ro cao.
Kết luận
AlphaEvolve là một bước tiến sâu sắc – không chỉ trong công cụ AI mà còn trong hiểu biết của chúng ta về chính trí tuệ máy móc. Bằng cách kết hợp tìm kiếm tiến hóa với lý luận và phản hồi từ LLM, nó định nghĩa lại những gì máy móc có thể tự chủ khám phá. Đây là một tín hiệu sớm nhưng quan trọng cho thấy các hệ thống tự cải tiến có khả năng tư duy khoa học thực sự không còn là lý thuyết. Nhìn về phía trước, kiến trúc nền tảng của AlphaEvolve có thể được áp dụng đệ quy cho chính nó: tiến hóa các bộ đánh giá của riêng mình, cải thiện logic đột biến, tinh chỉnh các hàm tính điểm và tối ưu hóa các quy trình đào tạo cơ bản cho các mô hình mà nó phụ thuộc. Vòng lặp tối ưu hóa đệ quy này đại diện cho một cơ chế kỹ thuật để khởi động hướng tới AGI. Khi AlphaEvolve mở rộng quy mô và sự can thiệp của con người giảm dần, nó có thể mang lại những lợi ích to lớn cho xã hội, trở thành một bản thiết kế cho những bộ óc nhân tạo thực sự tổng quát và tự tiến hóa đầu tiên.





