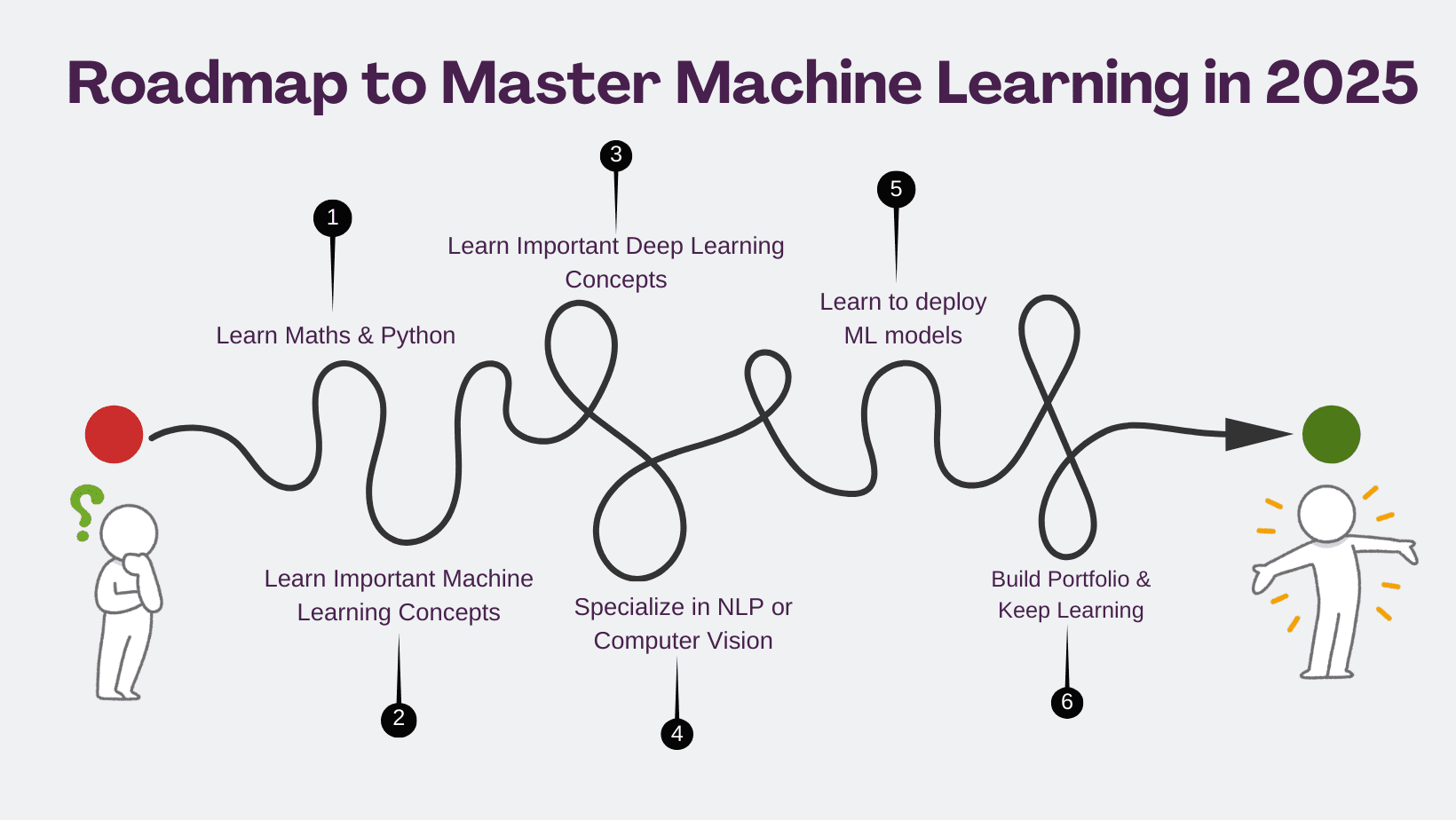
Key Takeaways
- Meta đã ra mắt một loạt công cụ bảo mật mới cho Llama AI, nhằm tăng cường an toàn và độ tin cậy cho các ứng dụng AI.
- Bộ công cụ Llama Protection bao gồm Llama Guard 4 (bộ lọc an toàn đa phương tiện), LlamaFirewall (trung tâm điều phối an ninh), và Llama Prompt Guard 2 (tối ưu hóa phát hiện tấn công prompt injection).
- Meta chia sẻ CyberSec Eval 4 (bộ công cụ đánh giá hiệu suất AI trong an ninh mạng) và khởi động Llama Defenders Program để hỗ trợ các chuyên gia và đối tác an ninh mạng.
- Các công cụ khác được chia sẻ bao gồm Automated Sensitive Doc Classification Tool (ngăn chặn rò rỉ dữ liệu nhạy cảm) và các giải pháp phát hiện âm thanh giả mạo (deepfake audio).
- Meta đang phát triển Private Processing cho WhatsApp, cho phép AI xử lý tin nhắn mà không tiết lộ nội dung cho Meta hoặc WhatsApp, tăng cường quyền riêng tư cho người dùng.
Nếu bạn đang xây dựng các ứng dụng trí tuệ nhân tạo (AI) hoặc tìm cách phòng thủ trước mặt trái của công nghệ này, Meta vừa tung ra một loạt công cụ bảo mật mới cho Llama AI. Đây là một tin vui cho cộng đồng phát triển và người dùng, hứa hẹn một tương lai AI an toàn hơn.
Meta Tăng Cường “Lá Chắn” Cho Llama AI: Loạt Công Cụ Bảo Mật Mới Ra Mắt
Meta đang thể hiện rõ cam kết của mình trong việc xây dựng một hệ sinh thái AI an toàn và đáng tin cậy. Việc ra mắt các công cụ bảo mật Llama mới, cùng với những tài nguyên hỗ trợ đội ngũ an ninh mạng khai thác sức mạnh AI để phòng thủ, là một bước tiến quan trọng. Động thái này cho thấy Meta không chỉ tập trung vào việc phát triển các mô hình AI mạnh mẽ mà còn rất chú trọng đến khía cạnh an toàn và đạo đức.
Đối với các nhà phát triển đang làm việc với dòng mô hình Llama, giờ đây họ đã có thêm những “vũ khí” lợi hại. Bạn có thể tìm thấy bộ công cụ Llama Protection mới nhất này trực tiếp trên trang Llama Protections của Meta, hoặc trên các nền tảng quen thuộc của giới lập trình viên như Hugging Face và GitHub. Sự sẵn có trên nhiều nền tảng giúp các nhà phát triển dễ dàng tiếp cận và tích hợp vào quy trình làm việc của mình.

Khám Phá Chi Tiết Các Công Cụ Bảo Vệ Llama AI Mới
Bộ công cụ bảo mật mà Meta giới thiệu lần này rất đa dạng, mỗi công cụ đảm nhận một vai trò cụ thể trong việc bảo vệ hệ thống AI. Hãy cùng tìm hiểu sâu hơn về từng “mảnh ghép” quan trọng này.
Llama Guard 4: Nâng Cấp Bộ Lọc An Toàn Đa Phương Tiện
Llama Guard 4 được xem là phiên bản cải tiến vượt bậc của bộ lọc an toàn tùy chỉnh do Meta phát triển cho AI. Điểm nổi bật nhất của Llama Guard 4 là khả năng đa phương tiện (multimodal). Điều này có nghĩa là nó không chỉ hiểu và áp dụng các quy tắc an toàn cho văn bản mà còn cho cả hình ảnh. Đây là một bước tiến cực kỳ quan trọng trong bối cảnh các ứng dụng AI ngày càng trở nên trực quan hơn, đòi hỏi khả năng kiểm soát nội dung đa dạng hơn.
Một thông tin đáng chú ý khác là Llama Guard 4 đang được tích hợp vào Llama API hoàn toàn mới của Meta, hiện đang trong giai đoạn thử nghiệm giới hạn. Việc tích hợp sớm này cho thấy tầm quan trọng của Llama Guard 4 trong chiến lược phát triển AI của Meta.

LlamaFirewall: Trung Tâm Điều Phối An Ninh Cho Hệ Thống AI
Tiếp theo là LlamaFirewall, một “tân binh” trong hệ sinh thái bảo mật của Meta. Công cụ này được thiết kế để hoạt động như một trung tâm điều khiển an ninh (security control centre) cho các hệ thống AI. Nhiệm vụ chính của LlamaFirewall là quản lý sự phối hợp giữa các mô hình an toàn khác nhau và kết nối với các công cụ bảo vệ khác của Meta.
Cụ thể, LlamaFirewall giúp phát hiện và chặn các loại rủi ro khiến giới phát triển AI phải “mất ăn mất ngủ”. Đó có thể là các cuộc tấn công “prompt injection” tinh vi nhằm đánh lừa AI, việc tạo ra mã nguồn tiềm ẩn nguy cơ (dodgy code generation), hoặc các hành vi rủi ro từ các plug-in AI. Kinh nghiệm cho thấy, việc quản lý tập trung các biện pháp an ninh sẽ hiệu quả hơn nhiều so với các giải pháp rời rạc.
Llama Prompt Guard 2: Tối Ưu Hóa Khả Năng Phát Hiện “Jailbreak” và “Prompt Injection”
Meta cũng không quên “tút tát” lại Llama Prompt Guard. Mô hình chính Prompt Guard 2 (86M) giờ đây đã được cải thiện đáng kể khả năng “đánh hơi” các nỗ lực “jailbreak” (bẻ khóa giới hạn của AI) và “prompt injection” (chèn các câu lệnh độc hại). Đây là những kỹ thuật tấn công phổ biến nhằm thao túng hành vi của các mô hình ngôn ngữ lớn.
Một điểm thú vị hơn có lẽ là sự ra đời của Prompt Guard 2 22M. Đây là một phiên bản nhỏ gọn và nhanh nhẹn hơn rất nhiều. Meta khẳng định rằng phiên bản này có thể giảm độ trễ và chi phí tính toán lên đến 75% so với mô hình lớn hơn, mà không làm suy giảm quá nhiều sức mạnh phát hiện. Đối với những ai cần phản hồi nhanh hơn hoặc hoạt động với ngân sách eo hẹp, đây chắc chắn là một sự bổ sung đáng giá.

Meta Không Chỉ “Xây Nhà” Mà Còn “Trang Bị Vũ Khí” Cho Đội Ngũ An Ninh Mạng
Không chỉ tập trung vào những người xây dựng AI, Meta còn hướng sự quan tâm đến các chuyên gia an ninh mạng – những người đang ở tuyến đầu trong cuộc chiến bảo vệ không gian số. Nhận thấy nhu cầu ngày càng tăng về các công cụ hỗ trợ AI trong việc chống lại tấn công mạng, Meta đã chia sẻ một số cập nhật quan trọng.
CyberSec Eval 4: Bộ Công Cụ Đánh Giá Hiệu Suất AI Trong An Ninh Mạng Cập Nhật
Bộ công cụ benchmark CyberSec Eval 4 đã được cập nhật. Đây là một bộ công cụ mã nguồn mở giúp các tổ chức đánh giá mức độ hiệu quả thực sự của các hệ thống AI trong các tác vụ an ninh. Phiên bản mới nhất này bao gồm hai công cụ mới rất đáng chú ý:
- CyberSOC Eval: Được xây dựng với sự hợp tác của các chuyên gia an ninh mạng từ CrowdStrike, framework này đặc biệt đo lường hiệu suất của AI trong môi trường Trung tâm Điều hành An ninh (SOC) thực tế. Nó được thiết kế để cung cấp một bức tranh rõ ràng hơn về hiệu quả của AI trong việc phát hiện và phản ứng với các mối đe dọa. Benchmark này sẽ sớm được ra mắt.
- AutoPatchBench: Benchmark này kiểm tra khả năng của Llama và các AI khác trong việc tự động tìm và vá các lỗ hổng bảo mật trong mã nguồn trước khi kẻ xấu có thể khai thác chúng. Đây là một khả năng rất được kỳ vọng, giúp giảm thiểu đáng kể rủi ro từ các lỗ hổng zero-day.
Llama Defenders Program: Tiếp Sức Cho Các Đối Tác An Ninh
Để đưa những công cụ hữu ích này đến tay những người cần chúng, Meta đang khởi động Llama Defenders Program. Chương trình này dường như tập trung vào việc cung cấp cho các công ty đối tác và nhà phát triển quyền truy cập đặc biệt vào một loạt các giải pháp AI – bao gồm cả mã nguồn mở, phiên bản truy cập sớm và có thể cả các giải pháp độc quyền – tất cả đều hướng đến các thách thức an ninh khác nhau. Đây là một cách tiếp cận thông minh, kết hợp sức mạnh cộng đồng và kinh nghiệm nội bộ của Meta.
Các Công Cụ An Ninh AI Khác Được Meta Chia Sẻ
Bên cạnh các công cụ chính cho Llama và đội ngũ an ninh mạng, Meta còn chia sẻ thêm nhiều giải pháp thú vị khác.
Automated Sensitive Doc Classification Tool: Ngăn Chặn Rò Rỉ Dữ Liệu Nhạy Cảm
Meta đang chia sẻ một công cụ bảo mật mà họ sử dụng nội bộ: Automated Sensitive Doc Classification Tool. Công cụ này tự động gắn nhãn bảo mật cho các tài liệu trong một tổ chức. Mục đích là gì? Để ngăn chặn thông tin nhạy cảm bị “tuồn” ra ngoài, hoặc để tránh việc vô tình đưa chúng vào một hệ thống AI (ví dụ như trong các thiết lập RAG – Retrieval Augmented Generation) nơi chúng có thể bị rò rỉ. Đây là một giải pháp thiết thực cho bài toán bảo vệ dữ liệu doanh nghiệp.
Giải Pháp Cho Vấn Nạn Âm Thanh Giả Mạo Bằng AI
Tình trạng âm thanh giả mạo do AI tạo ra (deepfake audio) ngày càng được sử dụng nhiều trong các vụ lừa đảo. Để đối phó, Meta chia sẻ Llama Generated Audio Detector và Llama Audio Watermark Detector với các đối tác. Các công cụ này giúp phát hiện giọng nói do AI tạo ra trong các cuộc gọi lừa đảo (phishing) hoặc các âm mưu gian lận tiềm ẩn. Các công ty lớn như ZenDesk, Bell Canada, và AT&T đã sẵn sàng tích hợp các giải pháp này. Sự hợp tác này cho thấy quyết tâm của Meta trong việc chống lại mặt trái của AI.
Hướng Tới Tương Lai: Private Processing – Đột Phá Về Quyền Riêng Tư Trên WhatsApp
Cuối cùng, Meta hé lộ một công nghệ tiềm năng rất lớn cho quyền riêng tư của người dùng: Private Processing. Đây là công nghệ mới mà họ đang phát triển cho WhatsApp. Ý tưởng là cho phép AI thực hiện các tác vụ hữu ích như tóm tắt tin nhắn chưa đọc của bạn hoặc giúp bạn soạn thảo câu trả lời, nhưng Meta hoặc WhatsApp sẽ không thể đọc được nội dung của những tin nhắn đó.
Meta đang tỏ ra khá cởi mở về khía cạnh bảo mật, thậm chí còn công bố mô hình đe dọa (threat model) của mình và mời các nhà nghiên cứu bảo mật “thử lửa” kiến trúc này trước khi nó được triển khai chính thức. Đây là một dấu hiệu cho thấy họ hiểu rằng cần phải làm đúng ngay từ đầu với khía cạnh quyền riêng tư, một vấn đề cực kỳ nhạy cảm.
Kết luận
Tổng thể, đây là một loạt thông báo quan trọng về bảo mật AI từ Meta. Họ rõ ràng đang đầu tư nghiêm túc vào việc bảo vệ các sản phẩm AI do chính mình xây dựng, đồng thời cung cấp cho cộng đồng công nghệ rộng lớn hơn những công cụ tốt hơn để phát triển một cách an toàn và phòng thủ hiệu quả. Những nỗ lực này không chỉ giúp nâng cao độ tin cậy của các mô hình Llama mà còn góp phần định hình một tương lai AI có trách nhiệm hơn. Việc Meta chủ động chia sẻ kiến thức và công cụ là một tín hiệu tích cực, khuyến khích sự hợp tác và minh bạch trong lĩnh vực đầy tiềm năng nhưng cũng không ít thách thức này. Bạn nghĩ sao về những công cụ mới này? Hãy chia sẻ ý kiến của mình nhé!